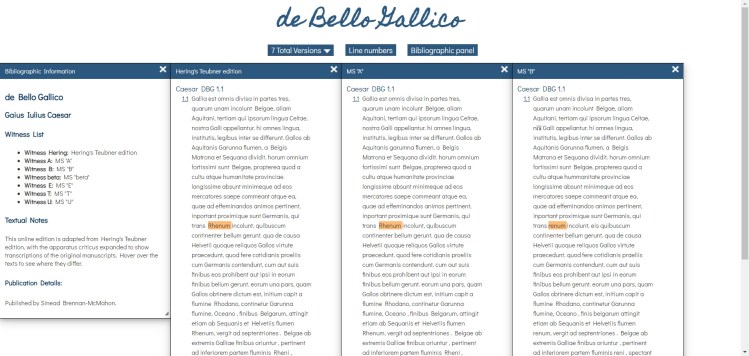
Sinead
Brennan-
McMahon

PhD candidate in Classics (ABD)
Knight-Hennessy Scholar
Data Science Scholar
Leadership in Teaching Fellow
Stanford University
I study sexuality in ancient Roman culture, and my long-term goal is to improve queer representation in Classics classrooms. I center Digital Humanities and Data Science techniques in my research and teaching.
I’m from Aotearoa New Zealand and have been living in California since 2019.
Current projects

1. Landscapes of sexuality: space, place and sex in ancient Roman culture, 100 BCE – 200 CE
I have found tentative evidence for a queer neighborhood in Pompeii, Italy, by studying the art that museums used to censor. Until now, queer people have mostly been archaeologically invisible in the ancient world, and our knowledge of their existence has come from pejorative literary texts. But by comparing where the art was displayed, any known non-patriarchal living arrangements (“chosen family”), and the literary accounts of sexuality that reference a spatiality, I have found clusters of “anti-normativity”, which may suggest a shared local community.
My project is a study of how regular Roman people interacted with nude and sexual art in their everyday lives, what it meant to them, and how they used sexuality to create identity in the urban environment. Dissertation advisor: Grant Parker; committee members: Hans Bork and Rolf Michael Schneider. I expect to complete a first draft in late 2024.

2. Hostile architecture and housing insecurity in Pompeii
I am writing an article on how unsheltered people lived in antiquity. I apply the theory of ‘hostile architecture’ to show how ancient town planners and private citizens made the urban environment inhospitable to unsheltered people. Expected completion: February 2025.

3. Ngram viewer for Latin
Inspired by the Google ngram viewer, I have developed an equivalent tool for the Latin literary canon using partial data from the Packard Humanities Institute (PHI), to visualise how the frequency of Latin words (lemmata) changed over time. Historians can use this tool to connect written evidence to chronologies, editors can use it to inform their decisions when preparing a new text for publication. I am using this tool in my Landscapes of Sexuality project to track how Latin sexual slang evolved in the first century CE.
The initial results need some help from a visual designer! But here is a baseline ngram of the word ‘ut’ in the Latin canon below, which is a lot more readable than only having the results in a table. The data in this visualisation is chunked by decade and normalised to the total wordcount. 
(click to expand)
Unlike the Google Books data, publication dates for ancient Latin texts are not always known to the year. For some texts we have date ranges, and for some of these ranges we know it’s not a uniform probability distribution function. In another visualisation (not pictured), I use Bayesian inference to estimate the frequency, to account for the dating uncertainty.
I made the ngram viewer in Python and SQL. I am currently working on expanding the data, putting an app online and making it user-friendly and accessible. The final version will be available here but for now the database is in a GitHub repo here. Expected completion: December 2024.

SCS 2025: ‘Queer Spaces in Pompeii?: Phallic Aesthetics and Shared Communities’